Conda的包管理
|
|
|
|
《文明是副产品》郑也夫

《理性乐观派》_[英] 马特 • 里德利
Matt Ridley

pandas 指引 : http://pandas.pydata.org/pandas-docs/stable/api.html#function-application-groupby-window
字符串的输入
|
|
合并 :运用加号 ( + ) 来进行合并字符串
空白
赋值与变更 : 必须将变更后的对象赋值,因为字符串是不可更改的; f = f.strip()
字符串 *(星号) 数字;表示字符串重复输出n次 print("." * 10)
转换 : str()
长度:len(string)
格式化
|
|
| 字符串 | 含义 |
|---|---|
| %d - digit | 整数 |
| %f - float | 浮点数 |
| %s - string | 字符串 |
| %x | 十六进制整数 |
| %% | 一个% |
如果你不太确定应该用什么,%s永远起作用,它会把任何数据类型转换为字符串
|
|
| 函数 | 描述 |
|---|---|
| int(x [,base]) | 将x转换为一个整数 |
| long(x [,base] ) | 将x转换为一个长整数 |
| float(x) | 将x转换到一个浮点数 |
| complex(real [,imag]) | 创建一个复数 |
| str(x) | 将对象 x 转换为字符串 |
| repr(x) | 将对象 x 转换为表达式字符串 |
| eval(str) | 用来计算在字符串中的有效Python表达式,并返回一个对象 |
| tuple(s) | 将序列 s 转换为一个元组 |
| list(s) | 将序列 s 转换为一个列表 |
| set(s) | 转换为可变集合 |
| dict(d) | 创建一个字典。d 必须是一个序列 (key,value)元组。 |
| frozenset(s) | 转换为不可变集合 |
| chr(x) | 将一个整数转换为一个字符 |
| unichr(x) | 将一个整数转换为Unicode字符 |
| ord(x) | 将一个字符转换为它的整数值 |
| hex(x) | 将一个整数转换为一个十六进制字符串 |
| oct(x) | 将一个整数转换为一个八进制字符串 |
|
|
元组是不可变的,类似字符串,不能在原处修改内容,但我们可以把它的类型做下转换,例如把一个元组转换为一个列表进行修改,之后再转换成元组。
|
|
方括号中索引值,半闭半开区间;左侧包括,右侧不包括
|
|
|
|
motorcycles.insert(0, 'ducati')根据位置直接删除 - del del motocycles[0]
根据位置删除 - pop()
motorcycles.pop()motorcycle.pop(1)根据值删除 - remove()
motorcycles.remove('string') / motorcycles.remove(obj)如果被弹出的元素不再需要使用,就选择del
cars.sort(reverse=True) 默认按字母顺序进行升序排列sorted(cars, reverse = True)cars.reverse()反转是在原有的基础上进行颠倒;不同于按倒序排列
Python计算列表list元素时从1开始。但索引是从0开始的;所以,在确定列表长度时会遇到差一
|
|
使用单数、复数的名称,有利于判断是单个列表元素还是整个列表
冒号的使用
缩进的代码必须是循环的一部分;没有缩进的代码只执行一次
|
|
|
|
字典推导式
>
集合推导式
|
|
|
|
|
|
一个key只能对应一个value,所以,多次对一个key放入value,后面的值会把前面的值冲掉
dict是用空间来换取时间的一种方法,并且需要牢记的第一条就是dict的key必须是不可变对象。
字符串、整数等都是不可变的,因此,可以放心地作为key
dict全称dictionary,在其他语言中也称为map
|
|
|
|
|
|
|
|
|
|
for key in sorted(user_0.keys()):set和dict的唯一区别仅在于没有存储对应的value,但是,set的原理和dict一样,所以,同样不可以放入可变对象
创建一个set,需要提供一个list作为输入集合
|
|
传入的参数
[1, 2, 3]是一个list,而显示的{1, 2, 3}只是告诉你这个set内部有1,2,3这3个元素,显示的顺序也不表示set是有序的>>> s = set([1, 2, 3])>>> s{1, 2, 3}
(age > 21) and (age_1 > 21)它是从上往下判断,如果在某个判断上是True,把该判断对应的语句执行后,就忽略掉剩下的 elif 和 else
只要x是非零数值、非空字符串、非空list等,就判断为True,否则为False
|
|
input()返回的数据类型是str,str不能直接和整数比较,必须先把str转换成整数
|
|
break语句可以在循环过程中直接退出循环,而continue语句可以提前结束本轮循环,并直接开始下一轮循环。
|
|
定义函数时,需要确定函数名和参数个数;
如果有必要,可以先对参数的数据类型做检查;
def语句,依次写出函数名、括号、括号中的参数和冒号:,然后,在缩进块中编写函数体,函数的返回值用return语句返回。return时,函数就执行完毕,并将结果返回。return语句,函数执行完毕后也会返回结果,只是结果为None。
|
|
如果想定义一个什么事也不做的空函数,可以用pass语句:pass语句什么都不做.
实际上pass可以用来作为占位符,比如现在还没想好怎么写函数的代码,就可以先放一个pass,让代码能运行起来。
|
|
返回多个值
|
|
|
|
|
|
允许传入0个或任意个参数,这些可变参数在函数调用时自动组装为一个tuple 【关键区别】。
|
|
|
|
|
|
允许你传入0个或任意个含参数名的参数,这些关键字参数在函数内部自动组装为一个dict 【关键区别】
|
|
限制关键字参数的名字,就可以用命名关键字参数
*后面的参数被视为命名关键字参数 【建议采用此种命名方法】
|
|
*了
|
|
- 命名关键字参数必须传入参数名,这和位置参数不同。如果没有传入参数名,调用将报错
- 使用命名关键字参数时,要特别注意,如果没有可变参数,就必须加一个
*作为特殊分隔符。如果缺少*,Python解释器将无法识别位置参数和命名关键字参数
|
|
|
|
函数名其实就是指向一个函数对象的引用,完全可以把函数名赋给一个变量,相当于给这个函数起了一个“别名” a =abs ; a(-1)
*args是可变参数,args接收的是一个tuple;**kw是关键字参数,kw接收的是一个dict。func(1, 2, 3),又可以先组装list或tuple,再通过*args传入:func(*(1, 2, 3));func(a=1, b=2),又可以先组装dict,再通过**kw传入:func(**{'a': 1, 'b': 2})。*args和**kw是Python的习惯写法,当然也可以用其他参数名,但最好使用习惯用法。*,否则定义的将是位置参数
|
|
函数体内部可以用return随时返回函数结果;
函数执行完毕也没有return语句时,自动return None。
函数可以同时返回多个值,但其实就是一个tuple。
|
|
每个函数应只负责一项具体的工作。若执行的任务太多,可在函数中调用另一个函数
在函数内部,可以调用其他函数。所谓递归函数,一个函数在内部调用自身本身 。
举个例子,我们来计算阶乘
n! = 1 x 2 x 3 x ... x n,用函数fact(n)表示,可以看出:fact(n) = n! = 1 x 2 x 3 x … x (n-1) x n = (n-1)! x n = fact(n-1) x n
所以,
fact(n)可以表示为n x fact(n-1),只有n=1时需要特殊处理
|
|
使用递归函数的优点是逻辑简单清晰,理论上,所有的递归函数都可以写成循环的方式,但循环的逻辑不如递归清晰。缺点是过深的调用会导致栈溢出。
针对尾递归优化的语言可以通过尾递归防止栈溢出。尾递归事实上和循环是等价的,没有循环语句的编程语言只能通过尾递归实现循环。
如果你已经把my_abs()的函数定义保存为abstest.py文件了,那么,可以在该文件的当前目录下启动Python解释器,用from abstest import my_abs来导入my_abs()函数,注意abstest是文件名(不含.py扩展名)
|
|
函数是Python内建支持的一种封装,我们通过把大段代码拆成函数,通过一层一层的函数调用,就可以把复杂任务分解成简单的任务,这种分解可以称之为面向过程的程序设计。函数就是面向过程的程序设计的基本单元。
变量可以指向函数
|
|
函数名也是变量
函数名其实就是指向函数的变量 。对于abs()这个函数,完全可以把函数名abs看成变量,它指向一个可以计算绝对值的函数!
传入函数
|
|
tuple也是一种list,唯一区别是tuple不可变。因此,tuple也可以用切片操作,只是操作的结果仍是tuple
字符串’xxx’也可以看成是一种list,每个元素就是一个字符。
|
|
|
|
|
|
|
|
for循环的对象统称为可迭代对象:Iterableyield的generator functionisinstance()判断一个对象是否是Iterable对象
|
|
dict迭代的是key。
如果要迭代value,可以用for value in d.values(),如果要同时迭代key和value,可以用for key, value in d.items()。
|
|
|
|
for循环中同时迭代索引和元素本身:
|
|
|
|
|
|
字典推导式
>
集合推导式
|
|
如果列表元素可以按照某种算法推算出来,这样就不必创建完整的list,从而节省大量的空间。
|
|
创建
L和g的区别仅在于最外层的[]和(),L是一个list,而g是一个generatorgenerator保存的是算法,每次调用
next(g),就计算出g的下一个元素的值,直到计算到最后一个元素,没有更多的元素时,抛出StopIteration的错误。
next()函数获得generator的下一个返回值
|
|
可以被next()函数调用并不断返回下一个值的对象称为迭代器:Iterator
Iterator对象,但list、dict、str虽然是Iterable,却不是Iterator。list、dict、str等Iterable变成Iterator可以使用iter()函数:
|
|
list、dict、str等数据类型不是Iterator。因为Python的
Iterator对象表示的是一个数据流,Iterator对象可以被next()函数调用并不断返回下一个数据,直到没有数据时抛出StopIteration错误。可以把这个数据流看做是一个有序序列,但我们却不能提前知道序列的长度,只能不断通过next()函数实现按需计算下一个数据,所以Iterator的计算是惰性的,只有在需要返回下一个数据时它才会计算。
Iterator甚至可以表示一个无限大的数据流,例如全体自然数。而使用list是永远不可能存储全体自然数的。
what :面向对象编程——Object Oriented Programming,简称OOP,是一种程序设计思想。OOP把对象作为程序的基本单元,一个对象包含了数据和操作数据的函数。
面向过程 vs. 对象编程:
在Python中,所有数据类型都可以视为对象。自定义的对象数据类型就是面向对象中的类(Class)的概念。
面向过程
|
|
|
|
类是抽象的模板,比如Student类,而实例是根据类创建出来的一个个具体的“对象”,每个对象都拥有相同的方法,但各自的数据可能不同。
类是创建实例的模板,而实例则是一个一个具体的对象,各个实例拥有的数据都互相独立,互不影响;
方法就是与实例绑定的函数,和普通函数不同,方法可以直接访问实例的数据;
通过在实例上调用方法,我们就直接操作了对象内部的数据,但无需知道方法内部的实现细节。和静态语言不同,Python允许对实例变量绑定任何数据,也就是说,对于两个实例变量,虽然它们都是同一个类的不同实例,但拥有的变量名称都可能不同:
class后面紧接着是类名,即Dog,类名通常是大写开头的单词,紧接着是(object),表示该类是从哪个类继承下来的,继承的概念我们后面再讲,通常,如果没有合适的继承类,就使用object类,这是所有类最终都会继承的类。
attribute为该类的属性;def 定义的该类的行为
|
|
__init__ : 初始化属性,此类方式在调用类时需传入外部参数
有了init方法,在创建实例的时候,就不能传入空的参数了,必须传入与init方法匹配的参数,但self不需要传,Python解释器自己会把实例变量传进去:
self :在类中定义属性,第一个参数永远是self,表示创建的实例本身。因此,在方法内部,就可以把各种属性绑定到self,因为self就指向创建的实例本身。
即,将外部参数的属性传入到内部
因为类时一个抽象的概念,在创建具体的实例之前,必须先有一个容器;
|
|
|
|
|
|
改完后,对于外部代码来说,没什么变动,但是已经无法从外部访问实例变量.__name和实例变量.__score了:
|
|
|
|
|
|
需要注意的是,在Python中,变量名类似xxx的,也就是以双下划线开头,并且以双下划线结尾的,是特殊变量,特殊变量是可以直接访问的,不是private变量,所以,不能用name、score这样的变量名。
有些时候,你会看到以一个下划线开头的实例变量名,比如_name,这样的实例变量外部是可以访问的,但是,按照约定俗成的规定,当你看到这样的变量时,意思就是,“虽然我可以被访问,但是,请把我视为私有变量,不要随意访问”。
|
|
|
|
一个类继承另一个类时,会自动获得另一个类的所有属性和方法。原有的类:父类;新的类:子类;
super().__init__将父类和子类关联起来,使其包含父类的所有属性
|
|
|
|
##主要函数
|
|
能用type()判断的基本类型也可以用isinstance()判断
|
|
spilt - 通过指定的分隔符将字符串拆分为一组子串
|
|
strip - 去除空格(含换行符),相当于对各个元素执行x.strip()
|
|
join - 联接其他字符串序列的分隔符
|
|
|
|
若为方法,也直接在符合的对象之后进行引用。
函数function —— A series of statements which returns some value toa caller. It can also be passed zero or more arguments which may beused in the execution of the body.
方法method —— A function which is defined inside a class body. Ifcalled as an attribute of an instance of that class, the methodwill get the instance object as its first argument (which isusually called self).
|
|
|
|
【Bound Method 和 Unbound Method】
method 还能再分为 Bound Method 和 Unbound Method, 他们的差别是什么呢? 差别就是 Bound method 多了一个实例绑定的过程!
A.f 是 unbound method, 而 a.f 是 bound method, 从而验证了上面的描述是正确的!
详细参见:https://segmentfault.com/a/1190000009157792
|
|
|
|
|
|
Surface data, not mining it(呈现数据,而非挖掘)
官方插件管理方式;( 登录 https://atom.io/)
首先你需要拥有一个 Github 账户,在 atom.io 看到什么好插件,只需点击 star 收藏。某天,你想一次把收藏插件全部安装,只需执行命令:
|
|
按照提示一步一步来就可以。更多操作执行
apm stars --help查看。
R实现自动化 - knitr 、 rmarkdown
《企业生命周期》_[美] 伊查克 • 爱迪思
《Managing Corporate Lifecycles 》_Ichak Adizes; 写于1996
在生命周期某一阶段属正常的问题有可能在另外一个阶段就是不正常的。
(未完)

前段时间本人利用业余时间,在网上查询各种资料,使用Hexo+Github的方式搭建起了我个人的博客——BrightLoong。相信网上已经有无数前辈写了类似的文章来记录如何搭建博客的过程和步骤,我也不哗众取宠或者班门弄斧了,把我在搭建博客中使用 资料做一个收集,同时也将我在搭建博客过程中遇到的坑列举出来,以及对应的解决方法,也是对搭建博客过程的一个记录,毕竟好记性不如烂笔头。那话不多说,接下来就是一个简单的介绍以及如何搭建的步骤(本文基本也是安照官方的步骤在介绍,我只是在有些地方记了下自己踩过的坑,强烈建议大家跟着Hexo官方文档操作)。
本文适用于Windows搭建
在Hexo官网上如此描述:Hexo is a fast, simple and powerful blog framework. You write posts in Markdown (or other languages) and Hexo generates static files with a beautiful theme in seconds.(Hexo是一个快速,简单和强大的博客框架。你可以使用Markdown(或其他语言)写博客,之后Hexo能在几秒钟生成具有美观主题的静态文件。)如果你想了解更多关于Hexo的东西,请移步Hexo官网。
Hexo是一款基于Node.js的静态博客框架,可以deploy到Github上,所以首先要在电脑上安装git和node.js,并在Github上注册自己的账号,由于这些东西不是本篇博客要涉及到的主要内容,你可以谷歌、百度,也可以参考我下面提供的链接。
你可以去官网下载Git,因为国外资源可能很慢,你也可以下载我在网盘上提供的Git镜像。具体如何使用,请参照廖雪峰老师关于Git的教程,如果你仅仅是想安装git那看看Git安装的那个章节
关于Node.js的安装以及配置,可以参照菜鸟教程上面关于Node.js安装配置的教程,上面也有下载的链接,本人就是参照上面安装的。具网上有些文章说,安装完成后最好重启电脑,以免之后无法使用hexo的相关命令,我倒是没有遇到,不过如果大家遇到这种问题就重启吧。
必须要在你安装了上述的Git以及Node.js之后才能进行Hexo的安装。
在任意地方点击右键,选择Git Bash Here
|
|
如果安装过程中遇到一下错误:
|
|
运行
|
|
打开一个目录,在这个地方点击右键选择Git Bash Here,执行以下命令
|
|
<folder>改为你想要的目录。
当然你也可以自己新建一个目录,比如我在F盘中创建了myblog目录,进入目录中点击右键选择Git Bash Here,直接执行以下命令
|
|
不管你用哪种方式,执行完毕后你会发现以下目录结构
|
|
执行以下命令来启动服务
|
|
如果启动过程中没有报错,此时你用浏览器访问http://localhost:4000/,是不是看到了一个Hello World的博客页面,hexo3.0使用的默认主题是landscape(之后我会讲如何更换主题,以及集成第三方的工具),而且此时的服务是本地启动的,别人并不能看到(继续我接下来的操作就好了)。
这个时候如果在浏览器没看到漂亮的博客页面怎么办,别急,先确认你在启动过程中是不是报错了,如过有的话估计是上面的操作有误,如果没有并且发现页面一直在加载中,估计是端口被占用了,我就遇到了这个问题。怎么办?把4000端口给杀死,还有更简单的——在hexo s命令后面加上启动参数,修改默认端口:hexo s -p <port>,比如我用的 hexo s -p 8000,现在重新访问http://localhost:8000/记得把地址的8000改成你自己对应的端口号,是不是看到了美丽的界面。
想要别人也访问到你的页面,跟着继续吧。首先在Github官网上注册一个账号,有账号的跳过注册,直接登录。登录后找到new repository按钮创建一个新的仓库。
然后填写repository name就行了,要注意的是:这个名字的格式必须为youname.github.io,并且必须和你的账户名相同,比如我的账户名是BrightLoong,我的地址就是brightloong.github.io(最开始我就是将name随意填写,虽然是这个格式但是根本访问不了,会报404的错误)。
最后,剩下的就是将本地文件推送到github上了,首先打开站点配置文件_config.yml,比如我的路径是:F:\myblog_bonfig.yml。找到最后的deploy属性,如果没有就自己添加,将配置修改为:
|
|
这个地方要注意的是属性后面的冒号必须要有一个空格,否则会报错
配置好之后使用以下命令将服务部署到github上。
|
|
使用hexo d命令,第一次会要求你输入用户名和密码,用户名和密码就是你注册github时候使用的用户名和密码。如果遇到以下错误:
|
|
运行
|
|
再执行上面的命令。
|
|
如果你没有配置Github的SSH,那么可能需要配置一下,你可以用以下命令查看一下
|
|
如果成功会有以下提示(我的账户名叫BrightLoong)
|
|
如果没有,可以参考博客git添加ssh-key查看config。
如果没有报错误,那么博客就已经搭建起来,并发布到Github上了,在浏览器输入youname.github.io就能看到自己的博客了,如果中途报错说未识别的用户名,那么如果你确定你填写是正确的,重复使用hexo d命令,我当时就遇到过这种情况,我估计是网络不好引起的。
既然博客已经搭建好了,那么不发几篇博文有就没有意义了,使用下面的命令来新建一篇叫做”brightloong”的文章。
|
|
命令执行之后,你会在你文件博客根目录的source/_post目录下找到你刚刚新建的md后缀的文件,比如我的是F:\myblog\source_posts\brightloong.md,hexo博客是使用markdown语法来书写的,如果不熟悉markdown语法可以快速的看一下markdown语法说明,或者是认识与入门Markdown,后者也有推荐一些不同平台下使用的编辑Markdown的工具,本人使用的是Cmd Markdown,它既支持在线的编辑,也可以下载下来使用。生成的md文件打开如下:
注意:在冒号后面一定要加上一个空格,否则在生成静态文件的时候会报错,并且也不能将其成功推送到github。
|
|
文章编写好之后,只用以下命令生成静态文件并推送到github上,执行完成后打开自己的博客页面,是不是发现刚刚编写的文章出现了;如果你想删除某一篇文章,那么在source/_post目录下找到对应的文章将其删除后,同样执行一下命令就OK了。
|
|
站点配置文件_config.yml是在你博客保存目录的根目录下,注意将它与主题配置文件进行区分,比如我保存的博客目录为F:\myblog那么我站点配置文件为F:\myblog_config.yml,我使用的主题是Next主题,所以我的主题配置文件为F:\myblog\themes\next_config.yml。下面我先介绍下站点配置文件,我将一些主要的配置做了注释,如果你想了解更多的配置的含义和作用,请访问Hexo官方教程查看。
|
|
搭建自己的博客,最吸引人的莫过于那千变万化的主题了,大家可以在Hexo官网上看到无数漂亮、大方、简洁的主题。本人使用的是简洁的Next主题,你可以选择你喜欢的下载下来,将其解压放入themes目录中,比如我的目录是F:\myblog\themes,然后修改我在上面提到的站点配置文件中的theme属性,为你刚刚放入themes目录中文件的名字(最好是对解压文件修改一个名字,否则名字可能会比较长,我把我下载下来的主题改文了next),做完这些之后并不代表你完成了,你还需要参考你所下载的主题所说的配置步骤进行相关的配置,由于不同的主题配置过程也尽不相同,大家根据自己下载的主题去配置,我在这里只说我使用的Next主题如何配置。
|
|
注意:从下面开始所说的都是Next主题的相关配置。
如果你使用的和我一样,也是Next的主题,那么你最好还是看官方提供Next使用文档,并且文档是中文版的,我也仅仅是讲一些容易被忽略的配置,以及我使用的配置,以及在使用过程中遇到的问题;至于如何更换头像,添加分类和标签页面、切换主题样式(Next主题包含3中样式)之类的,大家还是照着官方的做更好。
如何让网站前能显示自己想要的图标,我当时也是找了很久,最后发现是在主题配置文件(我的是F:\myblog\themes\next_config.yml)的最前面,有一个favicon属性,我把一个名字叫favicon.ico的图片(通过在线生成ico的网站)放到了F:\myblog\source下,然后配置如下:
|
|

首页的文章是不是默认展开了,显示出了整篇文章,怎么才能显示出如下的阅读全文的按钮。
在主题配置文件中找到auto_excerpt属性进行配置
|
|
你也可以在自己的博文中添加来决定在首页展示到什么位置(我就喜欢用这种方式),这个标签后的内容就不会展示到首页啦。
登录多说,登录后在首页选择“我要安装”。创建站点,填写表单。多说域名 这一栏填写的即是你的 duoshuo_shortname,如图:
创建站点完成后在 站点配置文件(我的是F:\myblog_config.yml) 中新增 duoshuo_shortname 字段,值设置成上一步红框中的值。
注意:新增字段的时候一定不要让字段前面有空格,否则会被认为是子字段,无法正确解析
|
|
多说评论中可以开启热评文章,在站点配置文件中增加字段:
|
|
开启后你可能会发现点击热评文章并不能跳转到对应的网页,进入多说后台查看,发现原来网址不正确,那简单,点击编辑修改成正确的网址就OK了。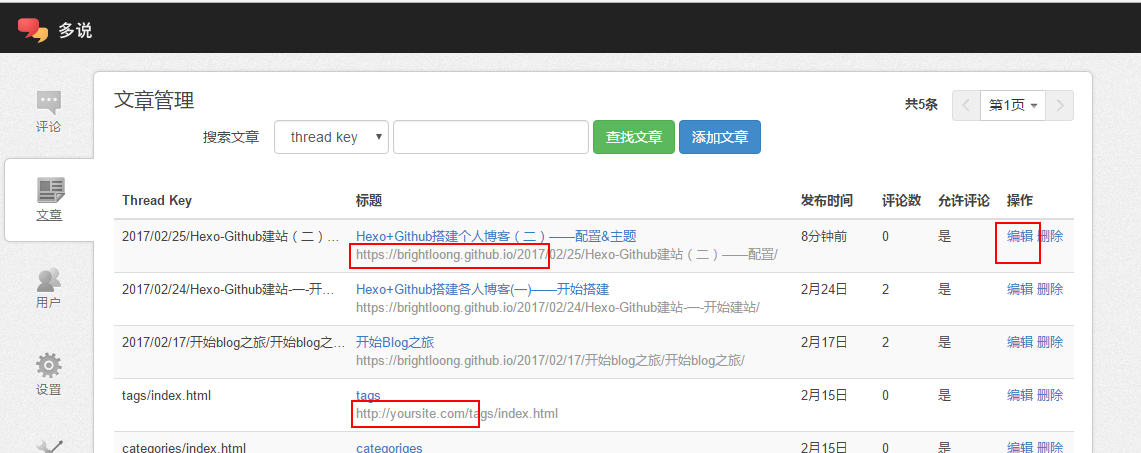
次数统计又leancloud提供,请参考由由Doublemine 贡献提供的为Next主题添加阅读次数统计功能
分享功能的集成是最坑的没有之一,我大概花了半天多的时间查找各种方法才将其解决,这里我先说官网的配置:编辑 站点配置文件,添加字段 baidushare,值为 true。
|
|
欢欢喜喜的打开自己的博客。咦!百度分享功能咋没有添加上啊。不急,听我慢道来。我在主题文件中发现一个文件
F:\myblog\themes\next\layout_partials\share\baidushare.swing,内容如下
|
|
注意到最开始的语句了吗if theme.baidushare.type === “button”,以及之后的else if theme.baidushare.type === “slide”什么意思,在theme下也就是主题配置文件中,baidushare字段下的type字段,我们打开主题配置文件(我的是F:\myblog\themes\next_config.yml),这个配置是不是被注释掉了:
|
|
修改之后,再启动,发现还是没有(如果你是用的本地启动用local的方式访问可能会看到百度分享功能已经出现了),这个是后打开浏览器F12的调试功能,是不是发现控制台报错了,提示你从https中去访问http的资源是不行的。不知道大家有没有看到刚刚我们修改的主题配置文件中,在上面有一段注释:
|
|
是的不支持https的方式,自己的域名是用https开头的(除非你自己购买了域名,如何购买更换域名请大家参考【Hexo+Github】域名和github绑定的问题)。并且,JiaThis等都不支持https,怎么办?